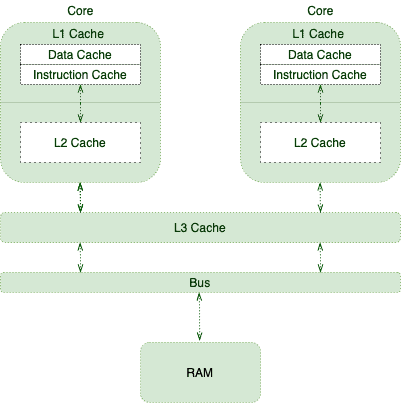
On multiprocessor systems (which are now appearing in the form of multicore processors— multiple CPUs on a single chip), visibility rather than atomicity is much more of an issue than on single-processor systems. Changes made by one task, even if they’re atomic in the sense of not being interruptible, might not be visible to other tasks (the changes might be temporarily stored in a local processor cache, for example), so different tasks will have a different view of the application’s state. The synchronization mechanism, on the other hand, forces changes by one task on a multiprocessor system to be visible across the application. Without synchronization, it’s indeterminate when changes become visible.
The volatile keyword also ensures visibility across the application. If you declare a field to be volatile, this means that as soon as a write occurs for that field, all reads will see the change. This is true even if local caches are involved—volatile fields are immediately written through to main memory, and reads occur from main memory.
It’s important to understand that atomicity and volatility are distinct concepts. An atomic operation on a non-volatile field will not necessarily be flushed to main memory, and so another task that reads that field will not necessarily see the new value. If multiple tasks are accessing a field, that field should be volatile; otherwise, the field should only be accessed via synchronization. Synchronization also causes flushing to main memory, so if a field is completely guarded by synchronized methods or blocks, it is not necessary to make it volatile.
It’s typically only safe to use volatile instead of synchronized if the class has only one mutable field. Again, your first choice should be to use the synchronized keyword—that’s the safest approach, and trying to do anything else is risky.
What qualifies as an atomic operation? Assignment and returning the value in a field will usually be atomic. However, in C++ even the following might be atomic:
➜ cat Atom.java
public class Atom {
volatile int i;
void f1() {i++;}
void f2() {i+=3;}
}
➜ javap -v Atom
Classfile /Users/nuc/tmp/Atom.class
Last modified 2022-8-5; size 316 bytes
MD5 checksum 2ccff8833c7994578e8f4e409da841a0
Compiled from "Atom.java"
public class Atom
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #4.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #3.#16 // Atom.i:I
#3 = Class #17 // Atom
#4 = Class #18 // java/lang/Object
#5 = Utf8 i
#6 = Utf8 I
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 f1
#12 = Utf8 f2
#13 = Utf8 SourceFile
#14 = Utf8 Atom.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = NameAndType #5:#6 // i:I
#17 = Utf8 Atom
#18 = Utf8 java/lang/Object
{
volatile int i;
descriptor: I
flags: ACC_VOLATILE
public Atom();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 1: 0
void f1();
descriptor: ()V
flags:
Code:
stack=3, locals=1, args_size=1
0: aload_0
1: dup
2: getfield #2 // Field i:I
5: iconst_1
6: iadd
7: putfield #2 // Field i:I
10: return
LineNumberTable:
line 3: 0
void f2();
descriptor: ()V
flags:
Code:
stack=3, locals=1, args_size=1
0: aload_0
1: dup
2: getfield #2 // Field i:I
5: iconst_3
6: iadd
7: putfield #2 // Field i:I
10: return
LineNumberTable:
line 4: 0
}
SourceFile: "Atom.java"
可以看到,volatile 字段被标记为 ACC_VOLATILE,其他并没有不同(在字节码层面没有插入别的操作)。核心操作就是 get/add/put。
看hotstop中putfield的实现,
//src/cpu/x86/vm/templateTable_x86_64.cpp
void TemplateTable::putfield(int byte_no) {
putfield_or_static(byte_no, false);
}
void TemplateTable::putfield_or_static(int byte_no, bool is_static) {
transition(vtos, vtos);
...
volatile_barrier(Assembler::Membar_mask_bits(Assembler::StoreLoad |
Assembler::StoreStore));
void TemplateTable::volatile_barrier(Assembler::Membar_mask_bits order_constraint ) {
// Helper function to insert a is-volatile test and memory barrier
if( !os::is_MP() ) return; // Not needed on single CPU
__ membar(order_constraint);
}
// Serializes memory and blows flags
void membar(Membar_mask_bits order_constraint) {
if (os::is_MP()) {
// We only have to handle StoreLoad
if (order_constraint & StoreLoad) {
// All usable chips support "locked" instructions which suffice
// as barriers, and are much faster than the alternative of
// using cpuid instruction. We use here a locked add [esp],0.
// This is conveniently otherwise a no-op except for blowing
// flags.
// Any change to this code may need to revisit other places in
// the code where this idiom is used, in particular the
// orderAccess code.
lock();
addl(Address(rsp, 0), 0);// Assert the lock# signal here
}
}
}
最终是通过在写数据的时候(putfield),加上lock addl实现的。
关于 lock指令
Intel 64 and IA32 Volume 2:
Causes the processor’s LOCK# signal to be asserted during execution of the accompanying instruction (turns the
instruction into an atomic instruction). In a multiprocessor environment, the LOCK# signal ensures that the
processor has exclusive use of any shared memory while the signal is asserted.
关于 addl(Address(rsp, 0), 0);
给rsp寄存器加0
如上,保证了被volatile标记的字段被更新时,会加锁(保证其他CPU不能访问),并把更新写回到主内存。